
ID systems analysed: Aadhaar
Case Study
Post date
19th November 2021
This written piece is part of PI's wider research into the tech behind ID systems around the world. Click here to learn more.
Overview
Aadhaar (Hindi for ‘foundation’) is India’s ID programme, the largest in the world, surpassing 1 billion sign ups in just under 6 years. This programme aims to give every citizen a unique, biometrically-verifiable identification number. Each user receives a card with their number on it, which can be cross-referenced with the biometric data held in a government database. An Aadhaar card is not a proof of citizenship but citizens are required to provide it to receive welfare payments and social services.
The programme was launched in 2010, led by Nandan Nilekani (co-founder & non-executive chairman of Infosys). Various stakeholders have been reported to have been involved in the promoting, deployment and development of Aadhaar. The initiative has garnered support from the Bill and Melinda Gates foundation and the World Bank, alongside a large number of private companies with hands-on involvement in the development and deployment of Aadhaar. However we have been unable to find a clear, comprehensive list of such stakeholders and their responsibilities. Additionally, in 2020 concerns were raised about the evaluation of the bidding process for awarding managed services infrastructure provider (MSIP) contracts.
By assigning design responsibilities to private sector actors, the overall development of the foundational ID solution were freed from governmental politics. However, no public consultations were recorded to discuss the design elements or requirements of such a solution.
The technology behind Aadhaar is proprietary, non-modular, and mandates the collection and processing of biometric data for identification and identification purposes, namely fingerprints, iris scans and facial scans.
For more context as to what these terms mean please refer to this introductory piece on different forms of digital ID systems.
Infrastructure makeup
Very few details are publicly available about the physical architecture of Aadhaar. There is only some high-level information about the enrolment and authentication processes available:
i - Enrolment- "Aadhaar registration follows a tiered process and is done either by governmental registrars or by third party agencies partnering with UIDAI. Three private sector vendors provide automatic biometric identification systems (ABIS) for enrolment centres. In an effort to reduce vendor lock-in, each ABIS vendor competes for work based on their registration throughput. The enrolment process requires a mix of demographic data (name, gender, date of birth as well as proof of address) and biometric data (10 fingerprints, iris scans and a photograph). Additional data such as a phone number or email address can be provided voluntarily. This data is then sent to the Central Identities Data Repository (CIDR) through a Secure File Transfer Protocol (SFTP) or through encrypted hard disks sent via approved carriers. The CIDR compares each new enrolee’s data with all the others enrolled in the database. This process is called de-duplication. If the enrolee clears this process, a 12-digit Aadhaar number is generated and posted to the individual. If enrolment is rejected, then the registrar is informed of the reasons of rejection and the next steps that need to be taken."
ii - Authentication- "Authentication is required for Indian residents to access state or central government benefits. This can be done via demographic authentication (based on Aadhaar number and demographic data), biometric authentication (based on Aadhaar number and fingerprint or iris scan data), multi-factor authentication or through an OTP (text message) based authentication mechanism. Biometric authentication is the most commonly used method. The authenticating system encrypts this data package and sends it to the CIDR via the authenticating service agency server (see Figure X for a simplified authentication process flow). The CIDR validates the received data package against its stored parameters and sends back a confirmation or rejection (yes/no) response. Security measures instituted by UIDAI include encryption of all data collected at enrolment agencies and decryption only at the CIDR. Contractually ABIS vendors cannot store source data. They are only allowed to store templates of enrolee data that are then sent for de-duplication. Once decrypted, all biometric data is stored offline. Only UIDAI approved authentication systems must be used. Authentication must be done through an encrypted protocol and digitally signed by an Authentication User Agency (AUA) or Authentication Service Agency (ASA)."
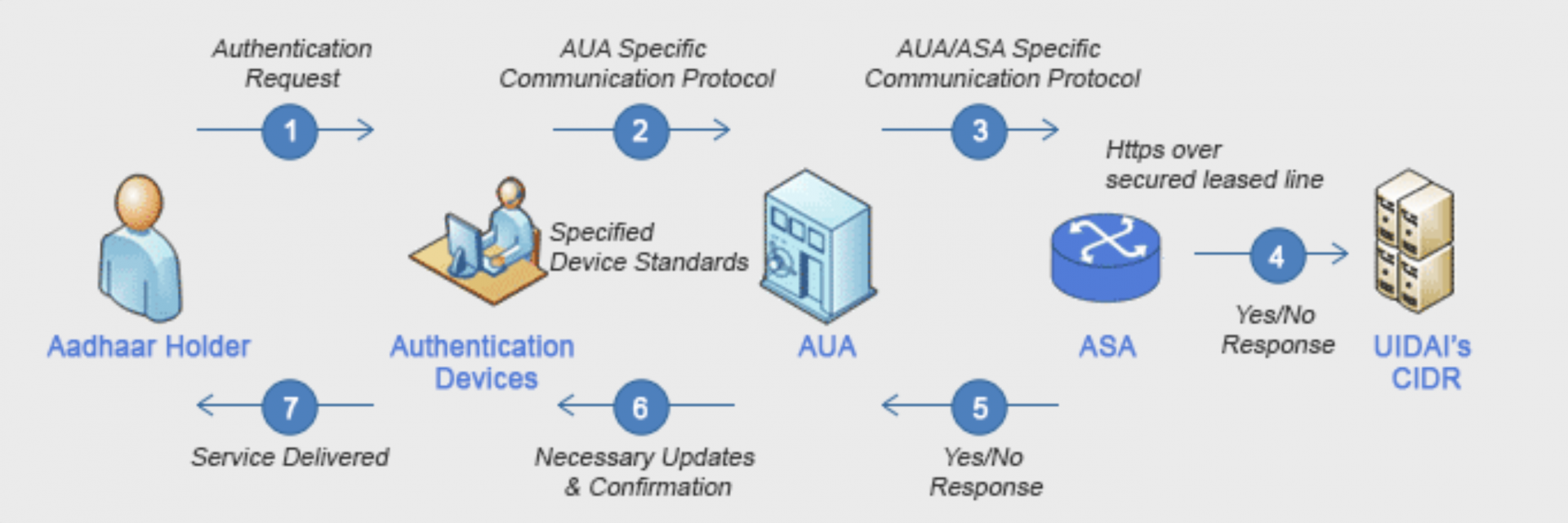
Overview of Aadhaar Enrolment and Authentication processes
The physical location of UIDAI’s data centre is public.
Encryption used
We were unable to find any relevant publicly available information on the encryption mechanisms used within Aadhaar.
De-duplication
UIDAI gives little to no publicly available information on how de-duplication is handled in practice, although the authority confirms that it performs both demographic and biometric de-duplication in order to try and achieve uniqueness of individuals in its database. Following up on this, earlier in 2021 UIDAI awarded a contract to Neurotechnology and TCS to Provide Biometric De-duplication to Aadhaar.
One of the particularly unique challenges in executing the UID project and ensuring individual uniqueness is its scale. As we will see, the case studies undertaken by the UIDAI present results based on extremely small datasets in comparison to the projects’s ultimate goal of including all of India’s population which is nearing 1.4 billion people. There is no consideration for the need to scale, which would then make the de-duplication exercise virtually impossible.
Let’s see why:
The UIDAI performed a matching analysis as a case study on two sets of 20,000 biometrics (i.e. 40,000 biometrics) where each set of biometric was matched against every other set of biometric in the data set. These are complex and time-consuming computations: for reference, for the used sample size of 40,000 biometrics, there is the need for (40,000 x 39,999)/2 = 799,980,000 comparisons to prove uniqueness of one biometric identifier against the remaining on the set.
This means that if we consider the whole population of India (approximately 1.4 x 109 as of November 2021) instead of an arbitrarily small sample we reach the conclusion that there will need to be approximately (1.4 x 109 x (1.4 x 109 - 1))/2 = 9.8 × 1017 comparisons. How would this translate to actual comparison time? Looking into average comparison times of different biometric matching methods, for argument’s sake let’s take the quickest comparison protocol which is in the order of magnitude of 10-8 seconds per comparison. We’ll then reach the conclusion that the time needed to compare one individuals’ biometrics against the rest of the database would be in the hundreds of years. And this is when we consider the best comparison time, increments in comparison time will make that number escalate even higher – and underpinning these estimations is the assumption that India’s population remains stagnant.
On top of this, there is another core question: does this comparison time allow UIDAI to perform good enough comparisons to guarantee uniqueness within the biometrics in UIDAI’s database? In reality it could take more than hundreds of years and not even then would UIDAI be able to make such a claim. This is because biometric match scoring is purely based on statistical probability (confidence level) rather than alphanumeric systems which have arbitrary scoring.
This confidence level is set beforehand and directly affects both comparison time on one side and UIDAI’s ability to claim biometric uniqueness in its database on the other.
When assessing screening software such as the one being used for biometric identification, one needs to look at its precision (its success at identifying true positives or not missing any true negatives) but also its recall (the rate of false positives and false negatives being generated).
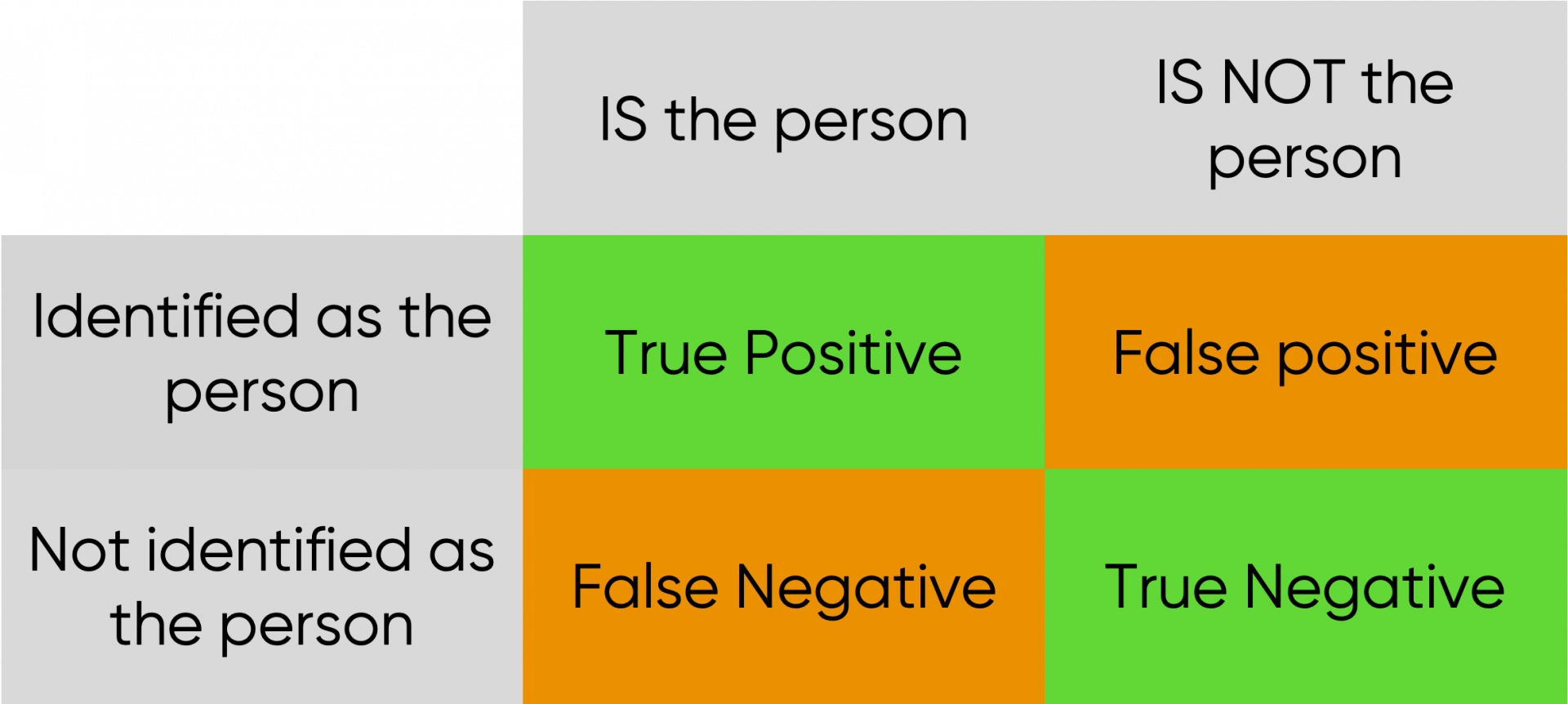
Possible cases when authenticating.
A true positive occurs when a person is successfully identified, while a true negative occurs when the system successfully identifies someone else's biometric as not a match for the target person being identified. A false positive occurs when the system wrongfully identifies the wrong individual as a match for the target person being identified, potentially leading to unauthorised access from other users, and finally a false negative represents the case where an individual is unable to be identified when it's in fact them identification, potentially leading to exclusion.
But how can the system overseeing authority tweak these results? As we said, biometric match scoring is based on statistical probability which varies according to the confidence levels set beforehand. These confidence levels relate directly to comparison speed and how thoroughly e.g. fingerprints are collected, represented and used for matching.
The lower the confidence level, the fewer data points will be compared, hence the quicker the comparison will be. At the same time, by using fewer data points, one sacrifices the idea of 'uniqueness' -- the amount of people with 'identical' biometric identifiers will increase. To better understand how and why this happens, we can draw a parallelism between this and how we are unable to tell the difference between two people from low resolution images.

Different subjects will have same low resolution representations.
On the other extreme, by increasing the level of confidence one will be using more data points and a closer representation of the individual's actual biometrics. This may seem like the obvious way to go, but in reality it brings other unwanted consequences. On one hand this will increase comparison time in such a way that it might make such a system obsolete for practical everyday use, and on the other hand, because biometrics are features that change through the course of our lives this will increase the rate of false negatives, as the system will become stricter in identifying potential changes in one's biometric identifiers.
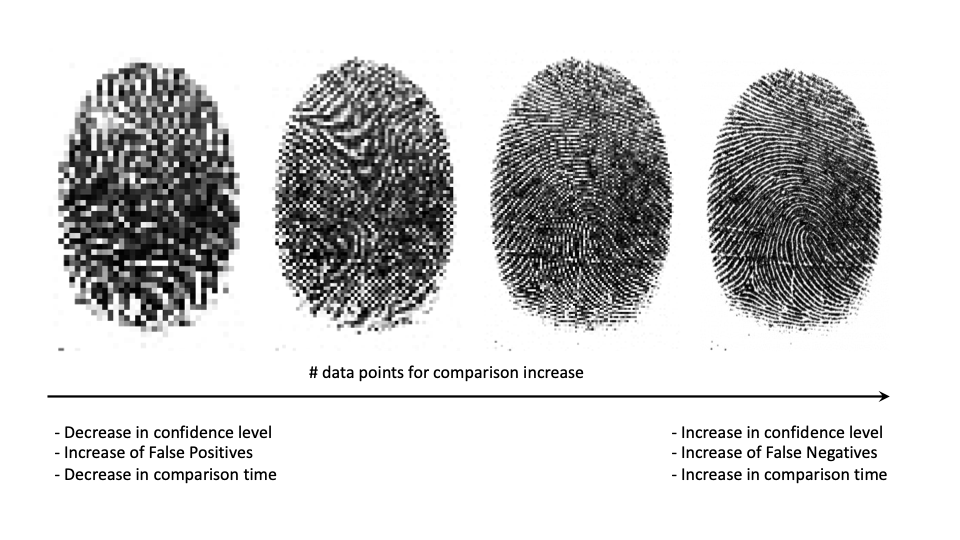
How confidence levels affect matching exercises.
Now let’s have a look at what UIDAI considered to be a good confidence level for biometric deduplication in their small sample case study, and what these values will mean when applied to the whole population of India.
In their case study, UIDAI aimed for a False Positive Identification Rate (FPIR) of 0.0025%, which means 2½ false positives cases on average for every 100,000 comparisons. This may not seem like a lot but, but earlier we saw that the number of comparisons needed when taking the whole population of India into account was approximately 9.8 × 1017, so the number of false positives generated in this case will be (9.8 × 1017) x (2.5 × 10-5) = 2.45 × 1013 FPIR. That’s 24,500,000,000,000 false positives to resolve within the whole population, which yields (2.45 × 1013)/(1,4 x 109)= 17,500 false positives for each person to manually resolve.
This being said, even keeping the FPIR fixed at a seemingly low value, we see that as the population size increases, so will the errors made by the system. This also shows that it is impossible for UIDAI to claim uniqueness within it’s amassed database which sabotages the idea of using biometrics for identification in the first place.
*This is a reference value, both dependant on and limited by the processing power of the machine performing the operations.
Principles of Engagement
The Unique Identification Authority of India (UIDAI) was established on the 28th of January 2009, with the objective to create unique identities for all Indian residents. The Aadhaar Act 2016 provided legal backing to the eID programme with UIDAI placed under the purview of the Ministry of Electronics and Information Technology.
Two principles, as per UIDAI, underpinned the design of this identity:
(a) robustness to eliminate duplicate and fake identities
(b) verifiable [confirming identity data on ID creation] and authenticable [confirming identity each time it is used] in an easy, cost-effective way
This is how UIDAI publicly communicates Aadhaar’s Vision and Mission:
Vision - Empower residents of India with a unique identity and a digital platform to authenticate anytime, anywhere.
Mission:
- To provide for good governance, efficient, transparent and targeted delivery of subsidies, benefits and services, the expenditure for which is incurred from the Consolidated Fund of India, to individuals residing in India through assigning of unique identity numbers.
- To develop policy, procedure and system for issuing Aadhaar number to individuals, who request for same by submitting their demographic information and biometric information by undergoing process of enrolment.
- To develop policy, procedure and systems for Aadhaar holders for updating and authenticating their digital identity.
- Ensure availability, scalability, and resilience of the technology infrastructure.
- Build a long term sustainable organization to carry forward the vision and values of the UIDAI.
- To ensure security and confidentiality of identity information and authentication records of individuals.
- To ensure compliance of Aadhaar Act by all individuals and agencies in letter and spirit.
- To make Regulations and Rules consistent with the Aadhaar Act, for carrying out the provisions of the Aadhaar Act.
Where
Country specific: India
Research indicates that Aadhaar is influencing how other countries outside of India look at ID and service delivery. There are also reports that the Indian government may export e-governance software products including Aadhaar to countries in Africa and Asia.
Examples of Abuse
Taking the vision and mission that UIDAI has published for Aadhaar as a starting point, and looking closer into how the foundational ID system has negatively impacted the lives of millions within India’s population, the abyss between the ideal and the practice becomes very evident.
Aadhaar has had countless reports of abuse over the years, including massive data leaks, exclusion from access to benefits and even issues around de-duplication.
Breaches
This list by itself contains almost 40 isolated cases of breaches between February 2017 and May 2018. The data leaked are not limited to Aadhaar numbers and demographic information. In some of the cases sensitive data such as data on pregnancy, people’s religion and caste and even bank details were leaked alongside Aadhaar numbers.
Exclusion
The Indian government has also made enrolment in Aadhaar a mandatory requirement to access a myriad of social protection schemes. This measure creates thick barriers in accessibility for a lot of people and has led to cuts in accessing food rations which has been linked to several deaths by starvation across the country.
Flawed system
In addition to this, the Indian government and the UIDAI have ignored privacy concerns as well as sample test results of its pilot project. As discussed above applying the seemingly acceptable outcomes of the pilot project to the whole population of India exposes a chronically flawed and inadequate system. And this has already been made evident through fails in deduplication and identification which have led to cases where one person somehow ends up getting two different, supposedly “unique”, Aadhaar numbers.
These example of abuse and the frequency with which they happen make it very clear that UIDAI is critically failing on keeping up with their vision and mission for Aadhaar. Be it in preserving the privacy of individuals, ensuring security and reliability of the infrastructure, inclusion of individuals, transparency regarding not only processes but also the makeup of the infrastructure, ensuring scalability and even on the most basic thing Aadhaar is conceptually supposed to provide - uniqueness.
Learn more
Our impact
Our fight


